TypeFriendly 0.1
| Copyright © Invenzzia Group 2008-2009 |
| Available under the terms of license: GNU Free Documentation License 1.2 |
| Generated: 26.03.2012 |
Table of Contents
- 1. Preface
- 2. Installation
- 3. Creating a new project
- 4. TypeFriendly
- 5. Appendix
- Table of Contents
1. Preface - 2. Installation
Next »
1. Preface
TypeFriendly is an utility tool written in PHP5 designed to generate and publish various texts in HTML formats, such as project documentations, user manuals, books and articles. It has been designed to be easy in use and it allows to achieve the first results immediately, a couple of minutes after you start the work. The script contains everything you need to write a clear, multilingual user manual or book, so that you do not have to implement the whole content generation framework from scratch.
The most important features of TypeFriendly:
- Modular project structure - the output book it is generated from text files and the structure and navigation are generated from the file names.
- Simple syntax - the text is written in intuitive and clean Markdown syntax.
- Multilingual tools - TypeFriendly allows you to create your projects in many language versions. It also contains a tool that shows whether the derived languages are up-to-date.
- Configurable output formats - currently, TypeFriendly is able to generate the documentation in XHTML (many pages) and XHTML (single page).
- Various add-ons such as syntax highlighting, references, class description fields.
- Navigation generators.
- It is portable - works under Linux, FreeBSD and Windows. All you need is the PHP interpreter available.
TypeFriendly is distributed under the terms of GNU General Public License 3, which means that you can use, modify and share it for free.
- Table of Contents
2. Installation - 1. Preface
« Previous - 3. Creating a new project
Next »
2. Installation
TypeFriendly is a command-line tool written in PHP5. In order to use it, you must have PHP 5.2 or newer with CLI support enabled.
Installing PHP
PHP is a popular scripting language used across the Internet to create dynamic websites. However, it can be also used to write ordinary system applications. In this chapter we will briefly describe, how to install PHP on your computer.
If you are a PHP programmer, PHP should already be installed on your computer. In this case you just need to check if the command-line interface mode is available in your installation.
Windows systems
The Windows binaries for PHP 5.2 can be downloaded in a form of ZIP archive from www.php.net. Extract the downloaded ZIP archive somewhere on your hard drive, for example C:\php\. Basically, this is all you need, but in order to run PHP, you have to specify the whole path to the php.exe file. To remove this inconvenience, you must add C:\php to your PATH environment variable.
Open the Control Panel and find System applet. In the tab Advanced select Environment variables and you will see a new window. Then, find the variable PATH in the System variables and click Edit to modify its value. After the semicolon ; add the path to the directory, where the php.exe file is located, for example:
...;C:\php\
Save everything and close the control panel.
Unix systems
Obtaining PHP is much easier on Unix systems, as they are usually equipped with various package management tools. For example, on Debian Linux, you can install PHP from the console:
apt-get install php5-common
apt-get install php5-cli
In other distributions the exact commands may be different and you have to refer to the documentation.
Usually, the packages are pre-configured to locate the executable file in one of the PATH locations, so you do not have to modify this environment variable manually.
Testing the installation
To test your PHP installation, open the operating system console (on Windows: Command line) and type:
php --version
If you see a message similar to the one below, everything went fine:
PHP 5.2.10RC2-dev (cli) (built: May 27 2009 18:48:36)
Copyright (c) 1997-2009 The PHP Group
Zend Engine v2.2.0, Copyright (c) 1998-2009 Zend Technologies
Installing TypeFriendly
Download the latest TypeFriendly archive from www.invenzzia.org and extract it somewhere on your hard disk. Basically, this is all you need, if PHP is installed correctly. Run the command line and move to the TypeFriendly directory with the cd command:
cd /path/to/TypeFriendly
To test the installation, try to build the TypeFriendly user manual provided with the application:
php typefriendly.php build "./docs/"
Unix users may try also the shortened form, if PHP executable is available under /usr/bin/php:
./typefriendly build "./docs/"
TypeFriendly should now rebuild the user manual you are reading now and the output version could be found in ./docs/output/.
- Table of Contents
3. Creating a new project - 2. Installation
« Previous - 3.1. Directory structure
Next »
3. Creating a new project
In this chapter we will describe, how to create your own book or documentation with TypeFriendly.
Setting up everything manually
In the next chapters we assume that you want to set up everything manually. The whole process is quite simple and lasts only a couple of minutes. If you are using TypeFriendly for the first time, we recommend to follow right this way, as it will introduce you into the project structure.
New project wizard
Since version 0.1.2, TypeFriendly offers a new project wizard run from the command line. The wizard automatically creates the base structure of the project in the specified directory using the default template and the provided information. In order to run the wizard, create a new empty directory and run the following command:
php typefriendly.php create "/path/to/directory"
You will be asked a couple of questions that will be used to personalize your newly created project.
- 3. Creating a new project
3.1. Directory structure - 3. Creating a new project
« Previous - 3.2. settings.ini file
Next »
3.1. Directory structure
The TypeFriendly project must have a proper directory structure. Create somewhere a new directory - in this manual we will mark it as /. Then, add some new directories and files to it:
/input
/en
/output
/sort_hints.txt
/settings.ini
The rules are simple. The /input directory contains the subdirectories representing the various language versions of the book. Inside them, we place text files with the content. TypeFriendly generates the output files to the /output directory, so it must have some write access there. Directly in the main directory, we put the configuration files common to all the language versions. The most important is settings.ini with the configuration. sort_hints.txt contains our own sorting rules. Their structure will be introduced in the next chapters.
Optionally, the language version subdirectories may also contain /input/LANGUAGE/media and /input/LANGUAGE/templates directories for:
- media files (images, charts, etc.)
- content templates
They will be also described later.
- 3. Creating a new project
3.2. settings.ini file - 3.1. Directory structure
« Previous - 3.3. Chapters
Next »
3.2. settings.ini file
This is the main configuration file that specifies the general properties of our project. It is an ordinary INI file with the syntax similar to the one listed below:
option1 = "value 1" option2 = "value 2" option3 = "value 3" ; comment
The semicolon begins a new comment which ends at the end of the line.
The base options are:
- title
- the project title.
- version
- project version.
- copyright
- copyrights to the project.
- license
- documentation license name.
- projectType
- the project type
- available values:
manual(default),documentation,article,book
Additional options:
- copyrightLink
- an URL to the copyright holder website.
- licenseLink
- an URL to the license text.
Project technical options:
- outputs
- the output list you are going to use in the project. They must be separated with commas.
- baseLanguage
- each documentation must choose its base language, which the original content is written in. It is important that the identifier of the language must be the same, as the language directory name.
- navigation
-
defines the way, how to generate "Previous" and "Next" links. Available values are:
- tree
- "Previous" and "Next" always point to the neighbors of the current chapter. If such a neighbor does not exist, the link is not displayed. This is the default value.
- book
- the "Previous" and "Next" links allow to travel across the whole documentation (like a book).
- showNumbers
- whether to display chapter numbers (values are true or false).
- versionControlInfo
- whether to display version control information from document tags (false by default).
Below, we can see a sample file. It is used to generate TypeFriendly manual:
; Base options title = "TypeFriendly" version = "0.1" copyright = "Invenzzia Group 2008-2009" copyrightLink = "http://www.invenzzia.org/" license = "GNU Free Documentation License 2.1" licenseLink = "http://www.gnu.org/licenses/fdl.html" projectType = "manual" ; Some rendering settings etc. outputs = "xhtml, xhtml_single" baseLanguage = "en" navigation = "book" showNumbers = true
- 3. Creating a new project
3.3. Chapters - 3.2. settings.ini file
« Previous - 3.4. File syntax
Next »
3.3. Chapters
The chapters are created as simple text files in the /input/language/ directory. Each of them consists of two parts:
- Header
- Content
In the header, there are several options (called "tags") that allow you to set the chapter title or connections to the other chapters. Under the header, we write the exact chapter content in the Markdown format. You can learn Markdown from this chapter, meanwhile we are going to show, how to manipulate the chapter order.
In every user manual or book, the chapters are organized in a specified order and they may contain subchapters. Sometimes we might want to leave the alphabetical order, for example if each chapter describes different functions and we need an index of them. In other cases, the chapters should be read one after another, as the latter ones may require the information from the earlier ones. With TypeFriendly, you can achieve all of these effects.
The chapter files use the *.txt file extension and the rest of the name is used to determine the dependencies. Each chapter has its own identifier constructed with letters, numbers, pauses and underscores. To specify that chapter A is the parent of B and C, we prepend the chapter A identifier to B and C identifiers and separate them with a dot. Below, you can find a sample list of chapter files:
preface.txtinstallation.txtinstallation.simple.txtinstallation.advanced.txtapi.txtapi.class.txtapi.class.function1.txtapi.class.function2.txtapi.interface.txtapi.interface.function1.txtapi.interface.function2.txt
Let's take a look at the installation chapter. We have a text file for it: installation.txt, where we can add some introductory text. But there are also two subchapters: installation.simple and installation.advanced. TypeFriendly sees that the first identifier is installation, so it links them to that chapter and generates a proper navigation structure. The API description is a bit more complex, because there are three levels. The api.txt contains an introduction, and inside it, we have the first class documented (api.class.txt). The class contains some functions, so we describe them in separate sub-chapters. Remember that if you have a file foo.bar.joe.txt, your project must have also the following files: foo.txt and foo.bar.txt, otherwise TypeFriendly will throw an error.
The default order for any chapter level is alphabetical:
api.txtapi.interface.txtapi.interface.function1.txtapi.interface.function2.txtapi.class.txtapi.class.function1.txtapi.class.function2.txtinstallation.txtinstallation.simple.txtinstallation.advanced.txtpreface.txt
Of course, in most cases this order makes no sense, as TypeFriendly put the preface and installation at the end of the user manual. To change the order, we use the sort_hints.txt file in the main project directory:
preface
installation
installation.simple
installation.advanced
api
api.class
api.interface
The sort_hints.txt file contains a list of the chapters in the new order. Note that you do not have to specify all the files here. If the alphabetical order suits you in some cases (for example, in the function list), you simply do not include this navigation level in the file.
You must either specify all the children of a chapter or none. TypeFriendly will throw you an error, if one of the subchapters is missing.
Tips:
The chapter identifiers do not change across the various language versions of your project, moreover - the translations use the same
sort_hints.txtfile, as the original text.The file name is also used to create the links manually in the text. Choose short and intuitive names that can be memorized easily.
TypeFriendly ignores the files with the different extension or with a tilde (~) character at the end of the name. This means you do not have to disable the backup options in your favorite editor.
See also:
- 3. Creating a new project
3.4. File syntax - 3.3. Chapters
« Previous - 3.4.1. Introduction
Next »
3.4. File syntax
A sample chapter file looks like this:
Title: Some title
Option1: Some value
Option2: Some value
OptionList:
- value 1
- value 2
---
Chapter content
In the header section, we put the tags in the way showed above. The Title is compulsory, but TypeFriendly recognizes much more. In fact, their list depends on the used output, because usually it's it which makes use of them. You can easily create a new output and start to use your own tags. It will be described later.
The header must be separated from the content by at least three pause characters --- surrounded with two single empty lines.
The content is formatted using the "PHP Markdown Extra" syntax with some extensions and modifications. You can find it in many websites, because the parsers are simple in use and very popular, so there is a chance you already know it. However, whether you know it or not, we encourage you to take a look at our syntax description, to see what improvements have been introduced by TypeFriendly. Similar documents can be also found at the parser website mentioned above.
See also:
- 3.4. File syntax
3.4.1. Introduction - 3.4. File syntax
« Previous - 3.4.2. Paragraphs and text
Next »
3.4.1. Introduction
Markdown was designed to be both easy in use and friendly in reading the source text. The source files can be helpful even without parsing them with TypeFriendly. We assume that the formatting characters should not dominate over the content and they should look like the formatting conventions used in e-mails or README files. There are also some similarities to the reStructuredText syntax. Markdown allows to use HTML and TypeFriendly modifications sometimes make use of it. In the next chapters, you will find a description of all the syntax elements.
TypeFriendly recognizes an extension to the original format, called Markdown Extra and created by Michel Fortin.
TypeFriendly uses the PHP Markdown Extra original parser written by Michel Fortin. Future releases of TF are going to include the newest versions of this parser.
The exact Markdown specification is currently under development. The new additions and solutions are expected to be added in the future, but the authors are going to keep the backward compatibility.
- 3.4. File syntax
3.4.2. Paragraphs and text - 3.4.1. Introduction
« Previous - 3.4.3. Emphasis
Next »
3.4.2. Paragraphs and text
A paragraph is one or more consecutive text lines. Paragraphs are separated with one or more empty lines. In Markdown, we assume that empty line simply looks like empty line, so the only the white characters are allowed there: spaces and tabulations. Remember that you should not do an indentation in the first line of a paragraph manually.
Lorem ipsum dolor sit amet ligula. Nam ultrices. Nunc sit amet justo. Integer magna ante, cursus justo vel quam nulla, at libero. Suspendisse et netus et metus eu pede massa.
Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos hymenaeos. Phasellus sapien enim ac eros. Fusce iaculis pede sit amet erat. Praesent dictum accumsan id, condimentum convallis.
Curae, Cras dictum eget, pede. Fusce blandit tempus arcu. Etiam tincidunt mattis egestas, nunc venenatis interdum, lacus. Vivamus malesuada fames ac erat. Suspendisse dignissim enim enim non eros. Aliquam in.
Lorem ipsum dolor sit amet ligula. Nam ultrices. Nunc sit amet justo. Integer magna ante, cursus justo vel quam nulla, at libero. Suspendisse et netus et metus eu pede massa.
Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos hymenaeos. Phasellus sapien enim ac eros. Fusce iaculis pede sit amet erat. Praesent dictum accumsan id, condimentum convallis.
Curae, Cras dictum eget, pede. Fusce blandit tempus arcu. Etiam tincidunt mattis egestas, nunc venenatis interdum, lacus. Vivamus malesuada fames ac erat. Suspendisse dignissim enim enim non eros. Aliquam in.
In the source file, the paragraph can be written in more consecutive text lines. They will not be broken with <br /> in the output text. This means we can format the text, for example like in e-mails.
Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet
sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum
sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
dolor sit amet, diam. In hac habitasse.
Although the paragraph consists of six lines in the source file, the output will still be one paragraph without line breaks:
Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum sociis natoque penatibus et ultrices bibendum, sem in lacus tellus dolor sit amet, diam. In hac habitasse.
To make a line break, we end it with at least two spaces and start a new line.
In the example below, we have replaced spaces with an underline characters _ to show where they are.
Lorem ipsum!__
Dolor sit amet!__
Sapien pede dictum.
Lorem ipsum!
Dolor sit amet!
Sapien pede dictum.
Special characters:
>,<and&Markdown allows to use HTML tags in the text, so the characters
> < &need a special treatment, if we want to display them.If you want to write about R&B music in HTML, you have to use the escaping codes or entities: R
&B. What is more, even URLs need such escaping, if they contain & symbol.Search <a href="http://images.google.com/images?num=30&q=linus+torvalds">photos</a>The Markdown parser is quite intelligent and guesses from the content, whether a character must be written as an entity or not. So if you wish to put a copyright symbol ©, you can use a normal HTML entity:
©.But let's get back to our R&B music. In this case, & will be changed into an entity automatically.
R&B musicThe
< >symbols are also escaped automatically in some cases. The following mathematical relation can be written without entities. Markdown will add them on its own:4 < 5
Horizontal lines
To insert a horizontal line (<hr />), you write at least three asterisks *, pauses - or underline symbols _ in the same line. They can be optionally separated with one space:
* * *
***
*****
- - -
---------------------------------------
- 3.4. File syntax
3.4.3. Emphasis - 3.4.2. Paragraphs and text
« Previous - 3.4.4. Code spans
Next »
3.4.3. Emphasis
Markdown uses the asterisks and underlines wrapped around the text to make it bold or italic. The emphasis style depends on the number of symbol. Single asterisk or underline wrapped around the text produces an italic font, and double produces bold one.
*single asterisks*
_single underlines_
**double asterisks**
__double underlines__
single asterisks
single underlinesdouble asterisks
double underlines
It does not matter, which symbol you are going to use. You must only use the same symbol to open and close the emphasized part.
To make a text that is both bold and italic, use three symbols:
***triple asterisks***
triple asterisks
The emphasis may be used inside a word:
Lorem*Ipsum*Dolor
LoremIpsumDolor
The rule above applies only to asterisks. The underline characters can be wrapped only around a whole word or sentence. Feel safe to write something like this:
use mysql_escape_string function
If you surround _ or * with single spaces, the text will not be formatted, and those characters will be simply displayed in the output.
You can escape the emphasis symbols with
\, if you do not want to parse them:\*this text is surrounded with asterisks\**this text is surrounded with asterisks*
- 3.4. File syntax
3.4.4. Code spans - 3.4.3. Emphasis
« Previous - 3.4.5. Headers
Next »
3.4.4. Code spans
You have probably already noticed some fixed width text on a yellow background inserted directly in the text. It is produced with backtick quotes ` wrapped around a text we wish to format:
Use the `print()` function to display some text.
Use the
print()function to display some text.
The formatted text can be surrounded with double backtick quotes, if it already contains such characters, to create the same effect:
`` This text contains a backtick quote (`) inside ``
This text contains a backtick quote (`) inside
If the quote is located at the beginning or end of the span, it can be separated with a single space that will not be displayed:
A single quote: `` ` ``
A text in backtick quotes: `` `something` ``
A single quote:
`A text in backtick quotes:
`something`
The symbols
<,>and&are always escaped inside the code span. The HTML tags are nod parsed then.Text:
Never use `<blink>` tag.Will produce:
Never use
<blink>tag.
See also:
- 3.4. File syntax
3.4.5. Headers - 3.4.4. Code spans
« Previous - 3.4.6. Links
Next »
3.4.5. Headers
Markdown supports two header systems: Setext and atx. Like paragraphs, they are block elements, which means that they must be separated with at least one empty line from other elements of the same type.
Setext notation
Here, the headers are "optically" underlined with equality characters = (first level) or pauses - (second level).
Header 1
========
Header 2
--------
The number of underline characters has no matter.
atx notation
This method supports all the header levels, using one to six hash symbols # before the header text.
# Header 1
## Header 2
##### Header 5
The text may be optionally ended with the same characters to make the header look better. The number of the characters does not have to match the header level.
# Header 1 #
## Header 2 ####
##### Header 5 #
TypeFriendly makes a small change to the original parser. The header level in the XHTML output is always decreased by 1, because the first level (
<h1>) is reserved for the chapter title. So, the header written as the first level will be the second level and so on. As a result, TypeFriendly supports up to 5 levels, not 6.
Sample headers:
Header 1
Header 2
Header 3
Header 4
Header 5
Anchors in headers
Headers allow to create anchors, which can be used to make a link from other parts of documentation to a particular fragment of a chapter.
The tag looks like this: {#anchor}. It is places after header's text in setext notation or on the end of a line in atx notation.
Header {#anchor}
========
### Header ### {#anchor}
##### Header {#anchor}
To make header anchors unique in whole documentation, TypeFriendly adds a prefix:
h:chapter_id:to each of them. So making a direct link to an anchor in this way:[link](#anchor)will not work.
- 3.4. File syntax
3.4.6. Links - 3.4.5. Headers
« Previous - 3.4.7. Images
Next »
3.4.6. Links
Markdown allows to insert links to other sites in three ways: directly in the text (linear), by a reference and automatically.
The first and the second one use the square brackets [ ] to surround the text that will be changed into the link.
Directly in the text
Here, we insert normal brackets right after the square ones where we write an URL. Markdown allows to specify the link title (to the title attribute in HTML). We specify it after the address and inside double quotes:
TypeFriendly was written by [Invenzzia](http://www.invenzzia.org)
TypeFriendly was written by [Invenzzia](http://www.invenzzia.org "Invenzzia")
TypeFriendly was written by Invenzzia
TypeFriendly was written by Invenzzia
By reference
The reference uses another square brackets written after the first ones. It is used to specify the link label. Optionally, the square brackets can be separated with one space:
This is an [example][id] of reference links.
This is an [example] [id] of reference links.
The reference definition looks like this:
[id]: http://www.example.org/ "Optional title"
The reference elements are:
- Square brackets with the label
- Colon
- At least one space or tabulation
- URL that the reference points to
- Optional link title written in double quotes, single quotes or brackets. It can be placed in the same line or in the new one, justified with spaces or tabulations.
The following lines give exactly the same result:
[id]: http://www.example.org/ 'Optional title'
[id]: http://www.example.org/ (Optional title)
[id]: http://www.example.org/
"Optional title"
Markdown allows to surround the link with angle brackets (< >):
[id]: <http://www.example.org/>
The reference definitions are for Markdown internal use only. They are removed from the output document.
The reference labels can use letters, numbers, spaces, punctuation marks, however they are case-insensitive.
Those two lines refer to the same label:
[some text][a]
[some text][A]
You can also ignore the label by writing empty square brackets []. Markdown will use the link name as a label then.
Example:
[Invenzzia][]
And the definition:
[Invenzzia]: http://www.invenzzia.org
This allows to produce longer labels with whole sentences, too!
[Invenzzia group][]
[Invenzzia group]: http://www.invenzzia.org
The reference definitions can be placed anywhere in the document, but they must be separated from the block elements (paragraphs, lists, etc.) with empty lines. You can write them after the paragraph where they have been used or at the end of the document.
Sample reference use:
We have 10 times more net traffic from [Google][1] than from [Yahoo][2] or [MSN][3].
In fact, [Google][1] is the most popular search engine.
[1]: http://www.google.com
[2]: http://www.yahoo.com
[3]: http://search.msn.com
With auto-labels:
We have 10 times more net traffic from [Google][] than from [Yahoo][] or [MSN][].
[google]: http://www.google.com
[yahoo]: http://www.yahoo.com
[msn]: http://search.msn.com
Why should we use references?
References make the source text easier to read and manage. Especially, very long URLs can be quite annoying when they are mixed with the content. References allow to throw them somewhere else.
Automatic links
Sometimes we want to display an exact URL in the text. Markdown offers a simple solution. We write the URL in the angle brackets and that's it:
Visit our website: <http://www.invenzzia.org/>
Visit our website: http://www.invenzzia.org/
This works also for e-mails. However, in this case Markdown will try to obfuscate the output HTML with entities.
Contact address: <company@example.org>
Contact address: company@example.org
Links to the other chapters
TypeFriendly registers in Markdown default references that point to all the chapters of your manual with their identifiers as labels. For example, to refer to the someClass description in api.classes.some-class, we write:
See also [this chapter][api.classes.some-class]
Links to anchors
Since TypeFriendly 0.1.3 it is allowed to make a link to anchors in the other chapters.
The syntax is the same as to a chaper and an anchor #anchor is located after the chapter id.
Check [this part of a chapter][api.classes.some-class#anchor]
To make a link to an anchor in the same chapter it is still required to use the above syntax and not to use
[link](#anchor). It is because TypeFriendly adds a prefix:h:chapter_id:to each header anchor to make them unique in the whole documentation.
- 3.4. File syntax
3.4.7. Images - 3.4.6. Links
« Previous - 3.4.8. Lists
Next »
3.4.7. Images
Markdown supports images and graphics much like the links. The main difference is the exclamation mark ! before the square brackets. The image syntax also supports references:


The alternative text goes to the alt attribute in the HTML code.
Image references are very similar to the link ones:
![Alternative text][id]
where "id" is a reference label. The image reference definition also looks familiar:
[id]: /path/to/image.jpg "Optional title"
More information can be found in the link chapter.
Images in TypeFriendly
Referring to the external images has absolutely no sense in the user manual which can be read and used off-line. In TF, the image files are located in the /input/LANGUAGE/media directory. Note that each language version has its own directory, so that you can translate also the texts on the pictures. During the processing, TypeFriendly moves this directory to /output.
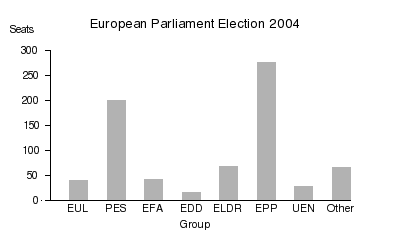
**Sample image**
Sample image

In our docs, the graph.png file is located in /input/en/media directory.
See also:
- 3.4. File syntax
3.4.8. Lists - 3.4.7. Images
« Previous - 3.4.9. Code blocks
Next »
3.4.8. Lists
Markdown supports unordered and ordered lists. They are block elements, so they must be surrounded by at least one empty line.
An ordered list is really easy to make:
Text
1. Element 1
2. Element 2
3. Element 3
Text
Text
- Element 1
- Element 2
- Element 3
Text
The numbers do not matter. You may write them in any order you want, they may repeat etc. because their only purpose is to make the source text look nice. The list below will give you the same effect:
3. Element 1
3. Element 2
68. Element 3
To produce an unordered list, we use asterisks *, pluses + or pauses -:
+ Element 1
+ Element 2
+ Element 3
text
* Element 1
* Element 2
* Element 3
text
- Element 1
- Element 2
- Element 3
- Element 1
- Element 2
- Element 3
We can use any of these symbols and the result will be the same.
The list symbols must be separated from the beginning of a line with 0 to 3 spaces. After the symbol, we write a text which must be followed with at least one space or tabulation.
The list element texts can be broken. To make the list look better, you can move the new lines to the same distance, as the first one, from the left text border:
* Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet
sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
* libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum
sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
However, this is optional and Markdown will accept also the following text:
* Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet
sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
* libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum
sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
- Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
- libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
If the list elements are separated with one empty line, their content will be put into paragraph tags <p>. Take a look at the example. The text:
* Element 1
* Element 2
* Element 3
will produce:
- Element 1
- Element 2
- Element 3
The same version with empty lines between list elements:
* Element 1
* Element 2
* Element 3
Will give us:
Element 1
Element 2
Element 3
Markdown allows to make more paragraphs in the list element. They must be surrounded with empty lines and begin with four spaces or a tabulation.
* Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet
sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
* libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum
sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
The paragraphs connected with lists produce some side effects. It is impossible to put two lists, one after another, because they will be merged:
1. Element 1 2. Element 2 3. Element 3 1. Element 1 2. Element 2 3. Element 3
- Element 1
- Element 2
- Element 3
- Element 1
- Element 2
- Element 3
The issue is still discussed and currently the recommended solution is to use a HTML comment
<!-- # -->between the lists to split them.
Nested lists
The nesting levels must be followed with spaces or tabulations.
Example:
1. Element 1
- Element 1.1
- Element 1.2
1. Element 1.2.1
- Element 1.3
2. Element 2
* Element 2.1
* Element 2.2
3. Element 3
Effect:
- Element 1
- Element 1.1
- Element 1.2
- Element 1.2.1
- Element 1.3
- Element 2
- Element 2.1
- Element 2.2
- Element 3
Lists with other elements of Markdown syntax
To use other elements of Markdown syntax in a list, they must be followed by four spaces or a tabulation, like paragraphs. Remember that a codeblock must be indented like other list elements, apart from its own indentation.
1. Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet
sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
sample codeblock
elit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
* Element 1
sample codeblock
* Element 2
libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum
sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
2. Something more.
Lorem ipsum dolor sit amet sapien pede dictum sapien massa sit amet sapien varius egestas, dapibus aliquam id, neque. Donec facilisis diam
sample codeblockelit, gravida turpis. Nullam at ligula. Aenean urna a purus fermentum
Element 1
sample codeblockElement 2
libero quis ipsum. Fusce ullamcorper ut, semper turpis egestas. Cum sociis natoque penatibus et ultrices bibendum, sem in lacus tellus
- Something more.
Pay attention to the number of spaces in the beginning of each line.
See also:
- 3.4. File syntax
3.4.9. Code blocks - 3.4.8. Lists
« Previous - 3.4.10. Tables
Next »
3.4.9. Code blocks
There are two ways of making pre-formatted code blocks. The first one is to insert four spaces or a tabulation before every line of the code:
Some paragraph here...
<?php
$part = "of our source code";
if($condition)
{
of_script('that we write');
}
?>
Some other paragraph....
Alternatively, we can insert at least three consecutive tildes ~ before and after the code block.
It is very important to write the same number of tildes in those two places.
Some paragraph here...
~~~
<?php
$part = "of our source code";
of_script('that we write');
?>
~~~
Some other paragraph.
However, this method does not allow to insert a code block into information frames or lists.
Syntax highlighting
TypeFriendly extends the code blocks with a feature of syntax highlighting. It is produced by GeSHi. The list of supported languages is available at the library website.
To turn on the syntax highlighting, we put the name of the language in square brackets: [language] in the line just before the code block. The language name must correspond to the language rule file in the /vendor/geshi/geshi directory.
Sample use
~~~
[php]
<?php
$part = "of our source code";
of_script('that we write');
?>
~~~
Result
<?php $part = "of our source code"; of_script('that we write'); ?>
The additional "language" is console, which changes the layout of the frame with the code to look like a operating system command line (dark background, white text):
php typefriendly.php build "./docs/"How to turn off the highlighting?
If a code block already contains a text enclosed in square brackets in the first line (for example, in INI files), follow it with a backslash symbol and the line will be displayed as a part of the code, not as turning on the syntax highlighting:
\[group] key = "in ini file"Of course, this applies only to the first line of the code block.
See also:
- 3.4. File syntax
3.4.10. Tables - 3.4.9. Code blocks
« Previous - 3.4.11. Definition lists
Next »
3.4.10. Tables
It is possible to add tables to text in Markdown. A simple table looks like this:
First header | Second header
-------------| -------------
Cell content | Cell content
Cell content | Cell content
First header Second header Cell content Cell content Cell content Cell content
The first line contains table headers. The second one are lines (----) that separate the headers from the table rows. The columns are separated with a vertical bar |.
Optionally, you may also add the vertical bars before and after each table line:
| First header | Second header |
|--------------| --------------|
| Cell content | Cell content |
| Cell content | Cell content |
The only content available in table cells are the inline elements, such as emphasis, links, images and code spans.
Align to left or right side
In tables it is possible to specify content alignment for each column. It is done by using colon : on the left, right or both sides of lines separating headers and content in columns. In the below example we optically aligned text in rows but it is not necessary.
| Header | Header | Header | Header |
| -------- |:------- | --------:|:--------:|
| Default | To left | To right | And |
| position | side | side | centered |
Header Header Header Header Default To left To right And position side side centered
Default CSS of the output (xhtml and xhtml_single) automatically makes cells centered.
- 3.4. File syntax
3.4.11. Definition lists - 3.4.10. Tables
« Previous - 3.4.12. Footnotes
Next »
3.4.11. Definition lists
Markdown supports a special list format called a definition lists. It consists of a term and an explanation, like in a dictionary. To create a definition list, we write a term in the first line, and in the next one, we put a definition followed by : and some spaces.
Apple
: Fruit of the apple tree.
Orange
: Citrus fruit, a type of berry.
- Apple
- Fruit of the apple tree.
- Orange
- Citrus fruit, a type of berry.
Definition lists support a group of explanations to the same term or a couple of terms to one explanation:
Word
: Unit of language that builds phrases.
: Fixed-size unit of bits that creates a natural data unit in computers.
TF
TypeFriendly
: A nice documentation generator written in PHP.
- Word
- Unit of language that builds phrases.
- Fixed-size unit of bits that creates a natural data unit in computers.
- TF
- TypeFriendly
- A nice documentation generator written in PHP.
Separating the definitions from terms with one empty line will enclose them into paragraphs.
Apple
: Fruit of the apple tree.
Orange
: Citrus fruit, a type of berry.
- Apple
Fruit of the apple tree.
- Banana
Citrus fruit, a type of berry.
Like the ordinary lists, the definition lists may contain other block elements, such as paragraphs or code blocks. They must be followed by four spaces or a tabulation.
Term 1
: This is a definition with two paragraphs. Lorem ipsum
dolor sit amet, consectetuer adipiscing elit. Aliquam
hendrerit mi posuere lectus.
Vestibulum enim wisi, viverra nec, fringilla in, laoreet
vitae, risus.
: The second defintion for the term 1 is also placed inside a
paragraph, because it is followed with an empty line.
Term 2
: This definition contains a code block and an ordered list:
some code
1. element 1
2. element 2
- Term 1
This is a definition with two paragraphs. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
The second defintion for the term 1 is also placed inside a paragraph, because it is followed with an empty line.
- Term 2
This definition contains a code block and an ordered list:
some code
- element 1
- element 2
Pay attention to the number of spaces in the beginning of each line.
- 3.4. File syntax
3.4.12. Footnotes - 3.4.11. Definition lists
« Previous - 3.4.13. Blockquotes and information frames
Next »
3.4.12. Footnotes
Footnotes work like the link references. They consist of two elements: the superscripted link in the text and the footnote definition at the end of the document.
This is a text with a footnote[^1].
[^1]: This is a footnote.
This is a text with a footnote1.
The footnote definitions can be located in any place, but they will be always displayed at the end of the document in the order they have been specified.
It is not possible to create two references to the same note. If you do this, the next notes will not be replaced.
Each footnote must have an unique name. It doesn't have to be a number - it can be also a text label.
The footnote name is used in the addresses and it does not influence the footnotes in the text.
The footnote name must be a valid value of an ID attribute in HTML.
TypeFriendly includes a chapter name to the footnote names.
Footnotes accept block elements, like paragraphs, lists, code blocks etc. All we need is to follow them with four spaces or a tabulation:
This is a text with a footnote[^1].
[^1]: This is a footnote.
Another paragraph of the footnote.
Markdown allows the first line to remain empty:
This is a text with a footnote[^1].
[^1]:
This is a footnote.
Another paragraph of the footnote.
-
This is a footnote. ↩
- 3.4. File syntax
3.4.13. Blockquotes and information frames - 3.4.12. Footnotes
« Previous - 3.4.14. Inline HTML
Next »
3.4.13. Blockquotes and information frames
Blockquotes known from the Markdown syntax specification behave a bit differently in TypeFriendly. But to begin with, let's see, how they look like.
If you saw some text e-mails, you are probably familiar with text quotes created with a chevron symbol > that starts every line. The same syntax has been applied to Markdown.
> This is a quote with two paragraphs. Lorem ipsum dolor sit amet,
> consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
> Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
>
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse
> id sem consectetuer libero luctus adipiscing.
This is a quote with two paragraphs. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing.
You do not have to quote empty separating lines:
> This is a quote with two paragraphs. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing.
Since the empty lines are included into a quote block, there is a problem with creating two blockquotes one after another. No matter how many empty lines you put, the two blocks will be always connected into one. Currently, an elegant solution of this problem is not known yet and for this moment we recommend to use an empty HTML comment as a separator, like
<!-- # -->which is used in our own documentation.
Blockquotes can be nested by adding more > characters at the beginning of a line:
> This is the first level of the quote.
>
> > A nested quote.
>
> We back to the first level.
This is the first level of the quote.
A nested quote.
We back to the first level.
Blockquotes can also contain other Markdown syntax elements, such as headers, lists, code blocks etc.
> ### A header ###
>
> 1. Element 1
> 2. Element 2
>
> Sample source code:
>
> return shell_exec('echo '.$input.' | '.$markdown_script);
Beware of the number of spaces after each element. It plays very important role in Markdown.
Information frames
In this manual, information frames are very common and you must have noticed them (yes, we mean those light yellow fields with an icon on the left). They are used to provide various information in a nice graphical form.
The frames use the blockquote syntax. The only difference is a special tag similar to those ones used in syntax highlighting: [type]. It specifies the type of the frame:
> [information]
> ### Information ###
>
> This is some important information for the documentation reader.
Information
This is some important information for the documentation reader.
Available frame types
[error]
[help]
[important]
[information]
[steps]
[stop]
[warning]
Disabling frames
If we do not want for some reason to display some text that looks like a frame tag in the first line, follow it with backslash
\.> \[important]Of course, this applies only to the first line of the quote.
- 3.4. File syntax
3.4.14. Inline HTML - 3.4.13. Blockquotes and information frames
« Previous - 3.4.15. Advanced use
Next »
3.4.14. Inline HTML
If Markdown syntax lacks of some functionality we need, we still can write some parts of the chapter in pure HTML. You do not need any special syntax, etc. - just write in HTML, if you need it.
The only constraint is that the HTML block tags, such as <div>, <table>, <pre>, <p> etc. must be separated with an empty line from the rest of the text and they must not be followed with spaces or tabulation. Otherwise, they would be wrapped with a paragraph. Here is a sample of a HTML table:
A paragraph
<table>
<tr>
<td>Something</td>
</tr>
</table>
Another paragraph
Beware - in this case the Markdown syntax is not parsed inside the tags. You have to use for example, <strong> instead of **emphasis**.
Span elements, like <span>, <del> or <sup> can be used everywhere. They can also replace some Markdown syntax - feel free to use <a> and <img> if you do not like the Markdown way.
Markdown syntax is still enabled in the span tags.
Markdown syntax in block elements
The original Markdown syntax does not allow to parse its own symbols inside block HTML tags. However, the parser has been extended with a special option which turns on the parsing on demand. You must add a special HTML attribute markdown whose value is 1:
<div markdown="1">
This *Markdown text* is still parsed! Yeah!
</div>
The result:
<div>
<p>This <em>Markdown text</em> is still parsed! Yeah!</p>
</div>
The parser recognizes various tag types. For example, if you turn on the syntax for <p>, only the span elements will be formatted, and the lists or quote blocks will remain unparsed. In some cases this may lead to problems:
<table>
<tr>
<td markdown="1">This *Markdown text* is still parsed!</td>
</tr>
</table>
The table cell accepts both block and span elements, but Markdown will parse only the second ones. If you need some block elements there, use markdown="block" attribute instead.
- 3.4. File syntax
3.4.15. Advanced use - 3.4.14. Inline HTML
« Previous - 3.5. File tags
Next »
3.4.15. Advanced use
Markdown is very sensitive to the number of spaces used for formatting complex block elements such as ordered lists and information frames. If you still have problems with some functions, check if you have used the correct number of spaces and line breaks. A good example too see, how to write in Markdown, is TypeFriendly manual itself.
Separating lists, quote and code blocks
If we want to create for example two ordered lists or code samples one after another, we have to make some tricks. By default, Markdown will connect them into one and this behavior comes from the specification. However, an elegant solution of this problem is not known yet and for this moment we recommend to use an empty HTML comment, like <!-- # --> which is used in our own documentation. Any other comment may be used, too.
1. Element 1
2. Element 2
3. Element 3
<!-- # -->
1. Element 1
2. Element 2
3. Element 3
> quote
<!-- # -->
> another quote
- Element 1
- Element 2
- Element 3
- Element 1
- Element 2
- Element 3
quote
another quote
Character escaping
Sometimes we do not want Markdown to parse certain characters in our text. We can escape them in a standard way by putting a backslash symbol \ before them. Here are some samples:
This is our paragraph \[ which contains \]() some code that would be interpreted as a link if not escaped.
~~~
\[the_section]
of_an = "ini file"
; will also not be highlighted
~~~
1410\. - a date of the Battle of Grunwald, not the ordered list beginning.
\> this will not produce a quote, too.
This is our paragraph [ which contains ]() some code that would be interpreted as a link if not escaped.
[the_section] of_an = "ini file" ; will also not be highlighted1410. - a date of the Battle of Grunwald, not the ordered list beginning.
> this will not produce a quote, too.
Of course, backslashes are removed from the output text.
Characters that can be escaped:
\ backslash
` backtick quote
* asterisk
_ underline
{} curly brackets
[] square brackets
() round brackets
> right chevron
# hash
+ plus
- minus (pause)
. dot
! exclamation mark
~ tilde
: colon
| vertical bar
3.5. File tags
Below, you can find a description of all the tags available in the chapter files. Most of them takes a string as a value, but some of them also support a group of values (an array). We specify them in the following way:
TagName:
- Value 1
- Value 2
- Value 3
Basic tags
- Title
- a full title of the chapter (required tag)
- ShortTitle
-
Alternative version of the title, contrary to the name it does not need to be shorter. This tag is used by TypeFriendly in following situations:
- As a document title and in breadcrumbs,
- In tags: SeeAlso, Extends, Implements, ExtendedBy, ImplementedBy, Throws, MultiExtends and Arguments,
- As HTML "title" attribute in links to other chapters.
If not set, the value is taken from Title.
- SeeAlso
- an array of identifiers to generate the "See also" section.
- SeeAlsoExternal
- like above, but allows to put external URLs. The address can be separated with a space from the URL text.
- Author
- document author
Example:
Title: Function foo()
ShortTitle: foo()
SeeAlso:
- reference.functions.bar
SeeAlsoExternal:
- http://www.example.com/ A sample website
Document status
- Status
- displays a
Statusfield in the output with the specified text. It may be used for various purposes. - FeatureInformation
- prepends the specified content template to the beginning of a chapter. You can find out more about content templates here together with the example.
API References
These tags are very helpful for making various Application Programming Interface references: function, class definitions, interfaces etc.
- Construct
- the programming construct the chapter describes. You may either enter your own construct name or use the predefined one. In the second case, TypeFriendly automatically translates the construct name to the other languages and checks what others tags can be used.
- Note that this tag is not obligatory. If you do not use it, TypeFriendly does not perform any extra checks and validations.
- Type
- shows the element type (may be used for various purposes)
- Visibility
- the element visibility (public, private etc.)
- Namespace
- allows to specify the element namespace.
- expects the identifier of a chapter that describes the namespace.
ENamespaceexpects the plain name of the namespace that does not have its own chapter in the documentation.- Extends
- base class.
- the tag cannot be used together with
MultiExtendsin the same chapter - expects the identifier of a chapter that describes the base class
EExtendsexpects the plain class name that does not have its own chapter in the documentation.- MultiExtends
- base classes (for languages that support multiple inheritance).
- the tag cannot be used together with
Extendsin the same chapter - expects the list of chapter identifiers that describe the base classes.
EMultiExtendsexpects the list of plain class names that do not have their own chapters in the documentation.- Implements
- implemented interfaces (for languages that support interfaces)
- expects the list of chapter identifiers that describe the interfaces.
EImplementsexpects the list of plain interface names that do not have their own chapters in the documentation.- ExtendedBy
- derived classes.
- expects the list of chapter identifiers that describe the classes that extend the current one.
EExtendedByexpects the list of plain class names that do not have their own chapters in the documentation.- ImplementedBy
- classes implementing the specified interface.
- expects the list of chapter identifiers that describe the classes that implement the current interface.
EImplementedByexpects the list of plain class names that do not have their own chapters in the documentation.- Mixins
- list of mixins used by the class.
- expects the list of chapter identifiers that describe the mixins.
EMixinsexpects the list of plain mixin names that do not have their own chapters in the documentation.- Traits
- list of traits used by the class.
- expects the list of chapter identifiers that describe the traits.
ETraitsexpects the list of plain trait names that do not have their own chapters in the documentation.- Throws
- the exceptions thrown.
- expects the list of chapter identifiers that describe the thrown exception classes.
EThrowsexpects the list of plain exception class names that do not have their own chapters in the documentation.- PartOf
- used with the
internal classconstruct to specify the top-level class that contains the current class. - expects an identifier of a chapter that describes the master class.
EPartOfexpects the plain class name that does not have its own chapter in the documentation.- Reference
- the function reference, i.e.
void foo(int a, int b [, int c]) - Arguments
- the list of function/method arguments
- the expected argument format:
Name: arg_name | Type: arg.type.chapter | EType: arg_type_name | Desc: argument description - the
TypeandETypetags are optional, however - if you decide to use them, they must be specified in all the arguments. - Returns
- the description what the function or method returns.
- File
- the file that contains the described item.
- Files
- the list of file names
- variant of
Filethat allows to specify more file names. - Package
- a package that contains the element.
- expects an identifier of a chapter that describes the package.
EPackageexpects the plain package name that does not have its own chapter in the documentation.- TimeComplexity
- specifies the time complexity of an function or algorithm.
- MemoryComplexity
- specifies the memory complexity of an function or algorithm.
Sample use:
Title: Class "foo"
Construct: class
Extends: reference.bar
Implements:
- reference.foo-interface
- reference.bar-interface
ExtendedBy:
- reference.joe
As you can see, the tags require the chapter identifiers by default. To specify the classes, interfaces etc. that are defined by some external libraries and your book does not cover them, you may use the extra tags prepended with the E letter:
Title: Class "foo"
EExtends: PDO
Implements:
- reference.my-interface
EImplements:
- Countable
- IteratorAggregate
As you can see, both of the versions can be used simultaneously in the same chapter.
The available predefined programming constructs for Construct tag:
class- a classinterface- an interfaceabstract class- an abstract classfinal class-a final classexception class- an exception classinternal class- a nested internal classfunction- a functionmethod- a methodstatic method- a static methodabstract method- an abstract methodaccessor method- an accessor method (i.e.setSomething(),getSomething()).final method- a final methodfinal static method- a final static methodfinal accessor method- a final accessor methodoptional method- an empty method that can be optionally implemented by the programmerconstructor- a class constructordestructor- a class destructormagic method- a magic method (i.e.__call()in PHP)operator- an overloaded operatorvariable- a variablestatic variable- a static variablemodule- a modulepackage- a packagenamespace- a namespacedatatype- a datatypestructure- a structure (like in C or C++)macro- a macromixin- a mixintrait- a traitexecutable- an executable filescript- a script
Behaviour description tags
They allow to document the expected element behaviour by defining side effects, start conditions, limitations, etc.
- StartConditions
- a list of descriptions of the start conditions.
- EndConditions
- a list of descriptions of the end conditions.
- SideEffects
- a list of descriptions of the side effects.
- Limitations
- a list of descriptions of the limitations.
- DataSources
- a list of data sources used by the element.
- expects the list of chapter identifiers that describe the data sources.
EDataSourcesexpects the list of plain data source names or descriptions that do not have their own chapters in the documentation.
Sample use:
Title: Returning a list of elements
StartConditions:
- at least one element exists
SideEffects:
- increasing the view counter by 1
EDataSources:
- "Elements" table
----
Description...
Version control tags
Information about the versions and version control.
- VCSKeywords
- specified a place where the version control system keywords can be expanded. The content of this tag is displayed in the output, if the
versionControlInfooption is enabled in the project configuration. - VersionSince
- the first version that contains the described item
- VersionTo
- the last version that contains the described item
Sample use of the tags:
Title: A sample page
VCSKeywords: $Id$
VersionSince: 1.0.2
VersionTo: 1.4.6
Now the version control systems, like Subversion, can expand their special keywords in the header, and moreover, if we enable one option, such information will be included in the generated output.
Document type tags
These are functional tags that help TypeFriendly to determine the chapter type.
- Appendix
- accepts a boolean value (true, false, yes, no). The tag helps creating appendices, providing the alphabetical enumeration for them according to the ordinary chapter order settings, and prepends the "Appendix" word to the title.
- 3. Creating a new project
3.6. Templates - 3.5. File tags
« Previous - 4. TypeFriendly
Next »
3.6. Templates
TypeFriendly 0.1.2 introduces the concept of content templates. The templates are extra text files with some Markdown-formatted text that can be inserted into the book chapters. They can be used to save some commonly used text parts in one place so that they can be easily modified.
The templates are stored in /input/LANGUAGE/templates/ directory as plain text files with name templateIdentifier.txt. They do not contain any header, just a plain Markdown-formatted content. For example, we can create a sample template experimental.txt:
> [warning]
> This is an experimental feature and the implementation details may be changed in the future.
Then, we may prepend this warning to our chapter:
Title: Sample chapter
FeatureInformation: experimental
---
Some text
Which will produce the following result:
Sample chapter
This is an experimental feature and the implementation details may be changed in the future.
Some text
Currently supported features
Currently, the content templates can be only prepended to the chapters with the FeatureInformation tag. Passing arguments to the templates is not allowed.
Future extensions
In the future versions, the implementation is going to be extended with the possibility of placing the templates in any part of the chapter and passing extra arguments that will improve the usability and spread the possible use of this feature. The exact date depends on the time required to create the necessary modifications to Markdown parser used in TypeFriendly.
See also:
- Table of Contents
4. TypeFriendly - 3.6. Templates
« Previous - 4.1. Command line interface
Next »
4. TypeFriendly
This chapter describes various aspects of TypeFriendly itself.
- 4. TypeFriendly
4.1. Command line interface - 4. TypeFriendly
« Previous - 4.2. Output interface
Next »
4.1. Command line interface
TypeFriendly is used only from the operating system command line. It supports both Windows systems and various Unix clones, including Linux. You can call the script in this way:
# Under Windows and Unix systems
php typefriendly.php
# Under Unix systems (since TF 0.1.2)
./typefriendly
TypeFriendly 0.1.0 and 0.1.1
The required parameter is always a path to the documentation directory (it means, to the directory that contains the settings.ini and other files). For example:
./typefriendly "./docs/"
Allowed options that must be provided in the alphabetical order are:
-c LANGUAGE- a tool for multilingual documentations. It compares the last modification time of the files and shows those ones in the derived language that are not up-to-date. Moreover it looks also for the missing files.
-l LANGUAGE- generates the documentation in the specified language (by default, the base language is chosen).
-o OUTPUT- generates the documentation, using the specified output only. It must be listed in the available outputs in the configuration.
Example:
php typefriendly.php "./docs/" -l en -o xhtml
To display the information about TypeFriendly, call the script without any parameters.
TypeFriendly 0.1.2 and newer
In TypeFriendly 0.1.2, the command-line interface has been improved and the usage of the script has changed. The first argument is always a command specifying what we want to do. In the second place, we should specify a path to the directory with the documentation we want to process and at last, we specify the options.
The available commands:
create - creates a new documentation from a template and saves it to the specified (empty) directory. TypeFriendly asks you four questions about the newly created document and uses the values to prepare the configuration file. The use:
./typefriendly create "/path/to/directory"build - builds an output version of the specified documentation. The available (optional) options are
-l(the language) and-o(the used output system). The use:./typefriendly build "/path/to/directory" -l en -o xhtmlcompare - compares the translation to the original version. This command requires the
-loption to select the translation../typefriendly compare "/path/to/directory" -l plversion - prints TypeFriendly version.
./typefriendly version
- 4. TypeFriendly
4.2. Output interface - 4.1. Command line interface
« Previous - 4.3. Multilingual books
Next »
4.2. Output interface
TypeFriendly allows to create your own output interfaces that can be used to generate the documentation. Some knowledge about PHP language is required in order to write them.
Parsing rules
TypeFriendly starts with creating a project object that allows to manipulate various aspects of the documentation. Then, the configuration is read and later, TF scans the input directory and puts the chapters in the correct order. At the end, the script loads the outputs and requests to generate the pre-processed results.
Each output is saved in a separate PHP file in the /outputs directory. It is a class named after the output that extends the standardOutput class and overwrites three methods described below. The class has one task: to pack the meta-data provided by the TypeFriendly into the HTML code. Unfortunately, the current version of Markdown supports only XHTML and it is not possible to generate, for example, LaTeX output. This feature will appear in the future versions of TypeFriendly.
The output system must take care of saving the result to the files. TypeFriendly provides only a directory path, where the result must be stored, but does not limit you in any other way. The programmer may use some of script interfaces.
API
standardOutput
An abstract class that must be extended by the output class. The methods:
init($project, $path)- called before the pages are processed. It takes the project object and the output directory path, where the result files should be saved.generate($page)- called for every chapter. The method takes an array$pagethat contains all the chapter meta-data. The indexes correspond to the tags used in the source file. The additional "tags" defined by TypeFriendly are described below.close()- called, when all the chapters have already been processed.
Additional tags in the meta-data defined by TypeFriendly:
Id- chapter identifierContent- chapter content, already processed by MarkdownNext- an identifier of the next page or NULLPrev- an identifier of the previous page or NULLParent- an identifier of the parent page or NULL
tfTranslate
It is used to translate the documentation messages to other languages.
tfTranslate::get()- returns thetfTranslateobject._($group, $id, ...)- returns a text$idin the group$group. Optionally, more parameters can be provided - their values will be placed in the message, if it contains necessary tags.
tfProject
The project object.
$fs- thetfFilesystemobject that describes the project directory.$tree- a public structure with the chapter tree. As an index, we provide the chapter identifier and we get an array with the meta-data of all the sub-chapters.getMetaInfo($name[, $exception = true])- returns the meta-data of the specified chapter.$nameis the chapter identifier. If the last parameter is set to false, the method throws an exception, if the requested page has not been found. Otherwise, it returns NULL.
tfFilesystem
This class represents the file system inside a directory. It allows fast and easy file/directory manipulation. We assume that filesystem means the directory mapped by an object of this class, where we can do the manipulations.
get($name)- returns the real path to the specified file in the file system. If the file does not exist,SystemExceptionis thrown.read($name)- returns the content of the specified file in the file system. If the file does not exists,SystemExceptionis thrown.readAsArray($name)- like above, but returns an entire file into an array.write($name, $content)- saves the$contentin the$namefile in the filesystem.
- 4. TypeFriendly
4.3. Multilingual books - 4.2. Output interface
« Previous - 5. Appendix
Next »
4.3. Multilingual books
This chapter describes, how to use multilingual tools available in TypeFriendly.
TypeFriendly assumes that one language works as a primary (base) language which is used to create the original text. The other languages are the translations (called derived languages). We set the primary language in the project configuration, using the baseLanguage option. Each language has a two-letter code, for example en, de, pl.
Translating chapters
In order to create a translation of our book, we create a folder in the /input directory whose name is the language code. Then we simply save there the translated versions of the original chapters. Note that the translated book must have the same structure, as the original one and you are not allowed to add extra chapters to it (they will be simply ignored). Below, you can find a correct chapter structure:
/input/en/ (our primary language)
preface.txt
chapter1.txt
chapter1.subchapter1.txt
chapter1.subchapter2.txt
chapter2.txt
chapter2.subchapter1.txt
chapter2.subchapter2.txt
/input/de/ (our translation to German)
preface.txt
chapter1.txt
chapter1.subchapter1.txt
chapter1.subchapter2.txt
chapter2.txt
chapter2.subchapter1.txt
chapter2.subchapter2.txt
The chapter identifiers in all the translations must be the same, as in the original book. There is no possibility to translate them, too.
You do not have to translate all the chapters at once. If TypeFriendly notices that the chapter is not translated, it uses the original content instead. Below, you can see an unfinished translation of the same book to French:
/input/fr/
preface.txt
chapter1.txt
chapter1.subchapter1.txt
chapter2.txt
In this case, the contents of chapter1.subchapter2.txt, chapter2.subchapter1.txt and chapter2.subchapter2.txt is taken from the primary language directory, that is /input/en/. This allows the maintainers of the primary language to introduce the new contents to the book that will be immediately visible in the translations and their maintainers may translate them later.
Translating the media files
Each language version of the book contains its own /media directory with the graphics etc. Similarly to the chapters, TypeFriendly takes the missing images to the translation from the primary language /media directory.
Translating the content templates
Each language version of the book contains its own /templates directory with the content template files. Similarly to the chapters, TypeFriendly takes the missing templates to the translation from the primary language /templates directory.
Translating the book interface
TypeFriendly also translates the book navigation messages, such as "Table of contents". The texts assigned to the messages are defined in the global /languages directory. The subdirectories represent each language currently available. The message is a part of a group and has its own unique ID used to find it. The groups are located in separate files that look like this:
; a comment identifier1 = "Text 1" identifier2 = "Text 2" identifier3 = "Text 3" ; etc.
To translate the book interface, create a new directory in /languages using the language code as the name, take the files from one of existing languages and simply replace the message texts. Remember - if one of the messages required by the book is missing, TypeFriendly tries to load it from the base language selected for the book. The exception is generated, if the message is missing there, too.
Currently, TypeFriendly provides the translated messages for three languages:
- English
- Polish
- Slovak
If you created a new translation, we would be grateful for sending it so that we could include it to the official TypeFriendly distribution and allow the rest of the world to use it.
- Table of Contents
5. Appendix - 4.3. Multilingual books
« Previous - A. Development and support
Next »
5. Appendix
Additional information about TypeFriendly.
- 5. Appendix
A. Development and support - 5. Appendix
« Previous - B. License and authors
Next »
Appendix A. Development and support
If you look for a support, visit our discussion board available in English language. We encourage to send new ideas and feature requests. If you found a bug, visit our bugtracker - remember that the bugs must be described IN ENGLISH ONLY!!!
The development versions of TypeFriendly can be downloaded from our Subversion repository. It supports anonymous read-only connections that allow to ''checkout'' its contents. The address is http://svn.invenzzia.org/svn/typefriendly. You can also watch the repository on-line: svn.invenzzia.org.
- 5. Appendix
B. License and authors - A. Development and support
« Previous
Appendix B. License and authors
The TypeFriendly script is developed by the Invenzzia group. The code was written by:
- Tomasz "Zyx" Jędrzejewski - design, core programming, documentation.
- Jacek "eXtreme" Jędrzejewski - outputs, Markdown issues, various fixes, default documentation layout, documentation.
The project uses the PHP Markdown Extra parser written by Michel Fortin and based on the John Gruber code. It is available under the modified BSD license included in its source code.
The project uses the GeSHi syntax highlighter written by Benny Baumann and available under GNU GPL license.
The documentation template uses Tango Icon Library, a part of Tango Desktop Project which is available under Creative Commons Attribution-ShareAlike 2.5 license.
Markdown syntax description is an adaptation of original Markdown Syntax page by Daring Fireball and PHP Markdown Extra description by Michel Fortin.
TypeFriendly is available under the terms of GNU General Public License 3. The text of the license is included into the package in the info/COPYING file. If you do not have this file, the license is available online here: http://www.gnu.org/licenses/gpl.html.
This documentation is available under the terms of GNU Free Documentation License 1.2. The text of the license is included into the package in the info/COPYING_DOCS file. If you do not have this file, the license is available online here: http://www.gnu.org/licenses/fdl.html.
Those licenses do not apply in any way to documentations created by you and processed by TypeFriendly, as well as the graphics created in a GPL editor is not a subject of GPL license.